User guide
This guide walks you through the process of fine-tuning large language models (LLMs) on the platform using a no-code interface, enabling custom model development without writing any code.
Pre-requisites
-
Sufficient Account Credits
- Ensure your account has enough credits for training and deployment. Add credits if necessary to avoid interruptions during resource-intensive operations.
-
Clean, Preprocessed CSV File
- Prepare your dataset in a CSV format.
- The data should be cleaned and preprocessed (no missing values, consistent formatting, etc.).
- Each row should represent a unique training example, and clearly labeled columns for the model’s input and output.
-
Available Instance for Deployment
- You’ll need a cloud GPU instance to deploy your tuned model. For guidance, refer to the instance launching steps outlined in the platform documentation.
Steps to Use No Code Tuning
1. Navigate to Model Tuning Page
- From the platform’s Home page, select LLM Tools.
- Then click Fine Tuning to reach the no-code model tuning dashboard.
2. Select Model Category and Model
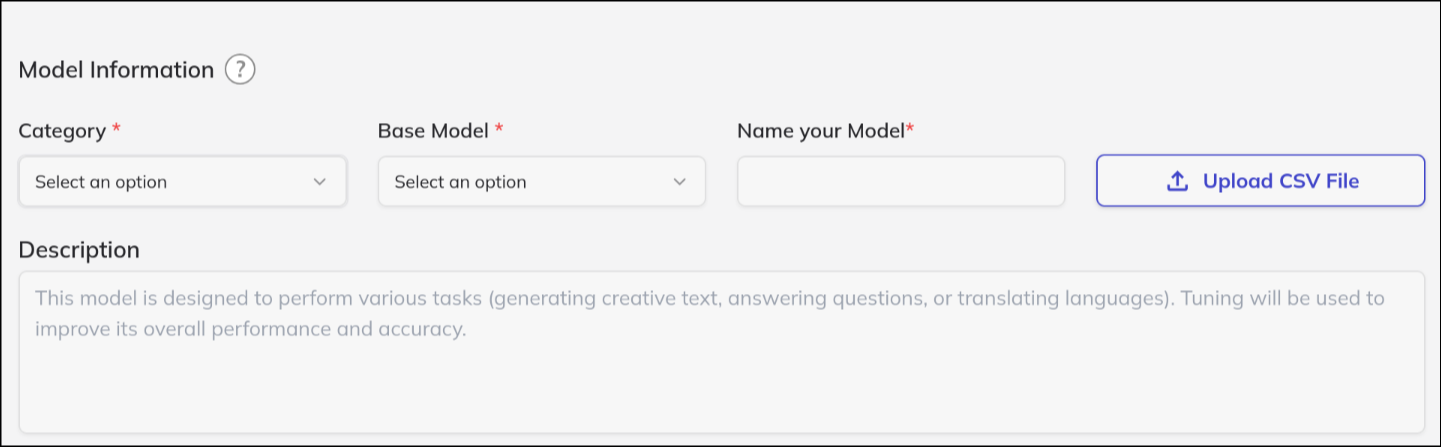
- Choose the model category that matches your use case (e.g., Text Generation, Code Generation).
- Pick a model suited for your task, such as Falcon-11B, by clicking on its name or selection button.
3. Upload Your CSV File
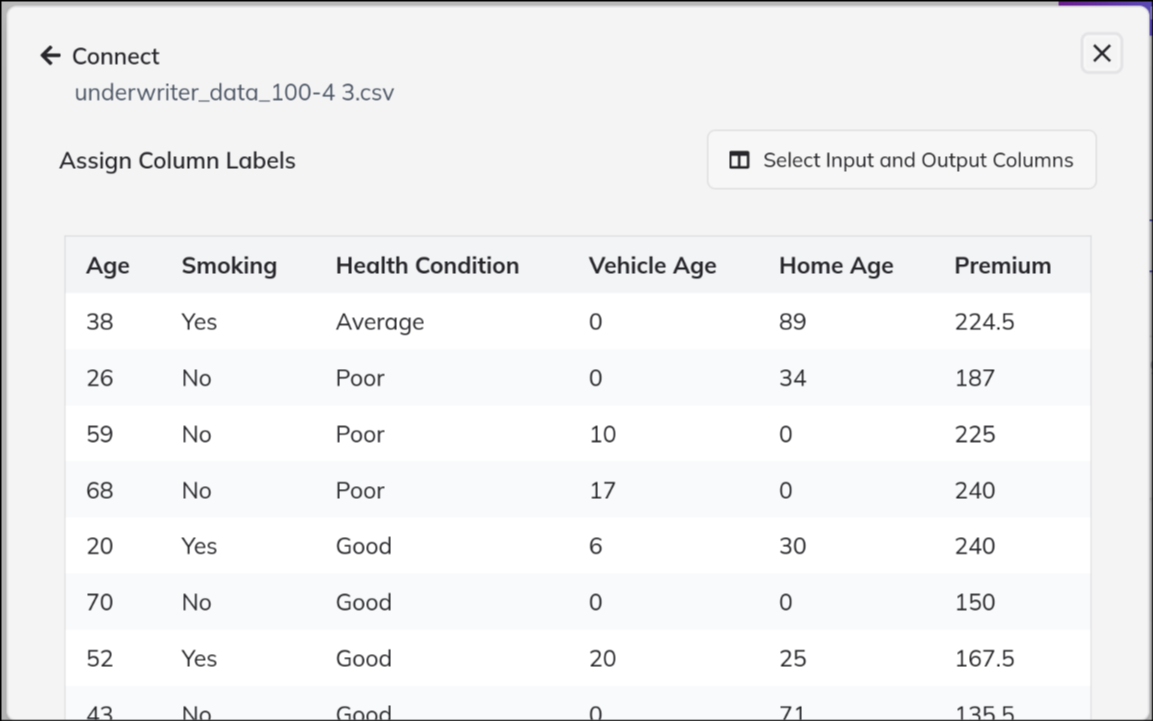
- Use the upload interface to add your prepared CSV file.
- Ensure your data meets the platform’s requirements; refer to documentation for supported formats and size limits.
- The system may provide a preview or validation before proceeding.
4. Set Training Parameters
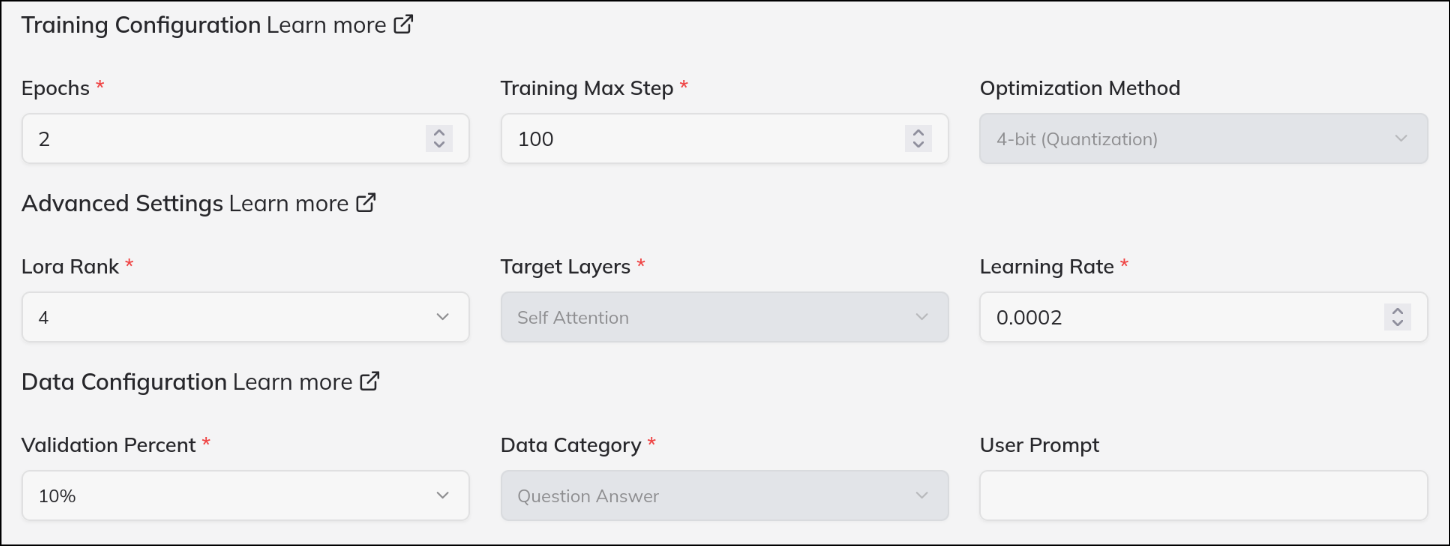
- Specify which columns in your CSV will be used for model input and desired output.
- Configure essential training options:
- Batch Size: Controls how many samples are processed before updating the model.
- Learning Rate: Determines the adjustment step size during model optimization.
- Epochs: How many times the training data is passed through the model.
- Additional advanced settings (if available) can further tailor the tuning process to your needs.
5. Initiate Tuning
- Review your configuration summary for correctness.
- Click Start Tuning to begin.
- The system automatically creates an isolated container to run your fine-tuning job, keeping it resource-contained and safe.
6. Check Tuning Status
- Monitor the progress of your job on the dashboard.
- Wait until the model’s status changes from “In Progress” or “Tuning” to Tuning Completed.
- Notifications or logs may be available for detailed tracking.
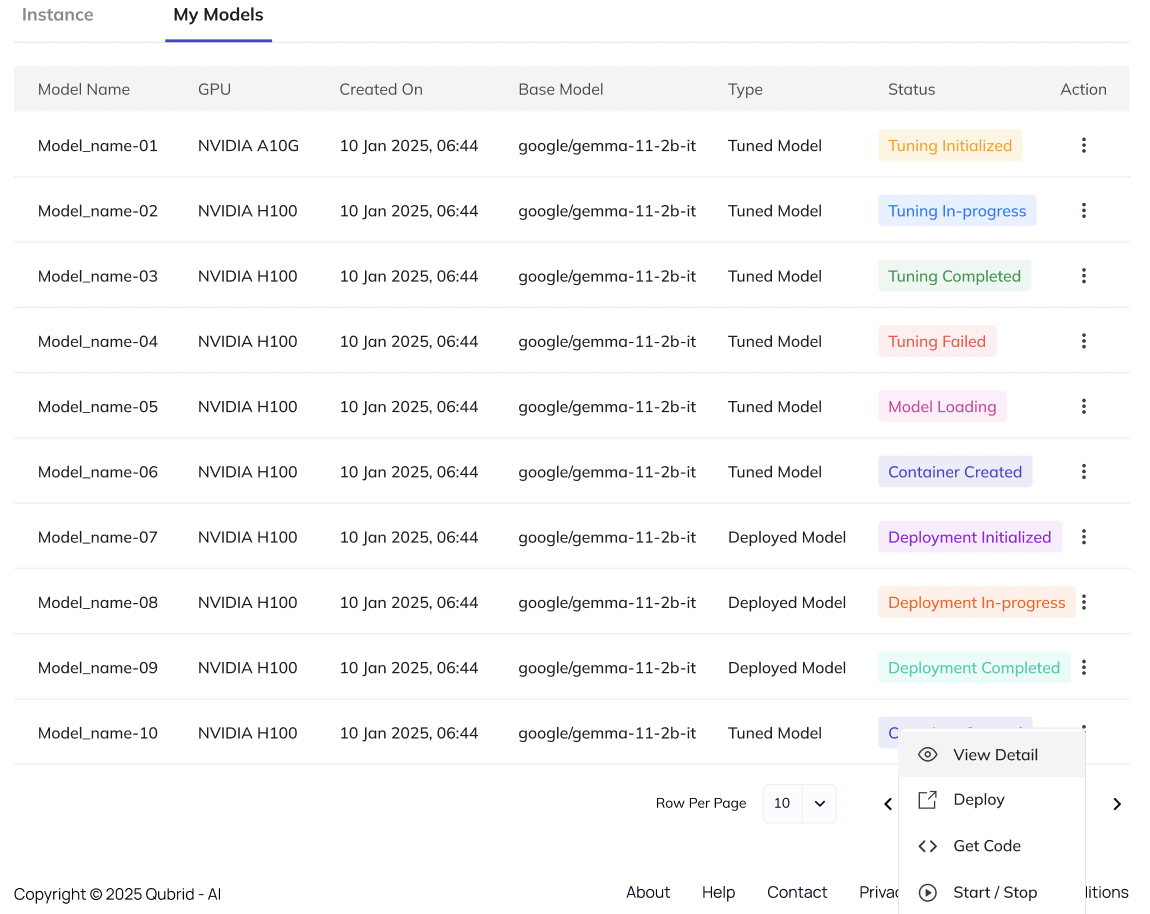
7. Deploy the Model
- When fine-tuning finishes, deploy the model:
- Go to Actions → Deploy.
- Select one of your active GPU instances. Note: Instances incur hourly billing once running.
- Deployment spins up the necessary environment to serve your model for inference.
8. Verify Deployment
- Confirm deployment was successful by checking that the model status is Deployment Ready on your dashboard or model listing.
- The platform may provide logs or a test endpoint for quick checks.
9. Use the Model
- Integrate and test the deployed model:
- GetCode: Instantly generate code snippets for terminal, Python scripts, or React frontend integration.
- Interactive UI: Use the built-in browser interface for rapid testing, parameter tuning, and live demonstration.
10. Stop or Delete the Model (Optional)
- Stop the Model: Pause resource usage and billing by stopping deployment when the model isn’t in use.
- Delete the Model: When finalized, delete it from the dashboard. Ensure status shows Deployment Stopped before deleting to safely free resources.
Additional Tips
- Data Backup: Always keep local copies of important datasets and trained models.
- Resource Monitoring: Track usage and budget from the dashboard.
- Parameter Optimization: Experiment with different training settings for optimal performance.
- Support: Reach out to helpdesk if you encounter issues or need advanced customization.
- Join our
Discord Groupto connect with the community and share your feedback directly or email us atdigital@qubrid.com.
- Join our
By following these steps, you can efficiently train, deploy, and utilize tailored LLMs for your use cases—entirely through a no-code interface, saving time and effort while ensuring robust results.